

咨询热线
HASHKFK
HASHKFK
od体育官方网站注册网址,od体育app官网下载,od体育最新登录网址,od体育平台,od体育app,od体育app下载,od体育靠谱吗,od体育,od体育下载,od体育官方网站,od体育官网,od体育投注,od体育下注,od体育买球,od体育世界杯,od体育欧洲杯,od体育赛事,od体育开户,od体育注册,od体育登录,od体育入口美国通过芯片管制与数字霸权的协同运作,构建了一套“硬技术封锁”与“软规则控制”相结合的战略体系,在芯片领域,美国通过《芯片与科学法案》和出口管制(如限制高端AI芯片及制造设备对华出口),试图从硬件层面遏制竞争对手的技术发展,同时联合盟友组建“芯片四方联盟”,强化对全球半导体产业链的控制。另一方面,在数字霸权领域,美国通过技术标准殖民(如将西方伦理准则嵌入AI审计体系)、法律长臂管辖(如依据《云法案》实施跨境数据管控)以及全球治理体系渗透(如通过OECD主导AI原则制定),从规则和制度层面植入其价值体系与利益结构。这两大手段相互关联:芯片管制为数字技术提供物理基础保障,而数字霸权则通过规则和标准确保美国在技术生态中的持续主导,共同形成对全球技术格局的“软硬双重控制”。
操作系统和数据库是软件生态的关键。统信UOS和麒麟OS成为国产桌面和服务器操作系统的主力,通过开源协作和生态适配,实现了与数百万软硬件产品的兼容。华为鸿蒙系统(HarmonyOS)实现全栈自研与全场景覆盖。HarmonyOS NEXT通过分布式架构整合CPU/GPU/NPU算力,实现任务智能调度与能效优化,其生态设备数突破千万,覆盖手机汽车、智慧屏等场景,并推出鸿蒙电脑(MateBook Pro/Fold),支持WPS、微信等超1000款应用,实现移动端与桌面端生态统一。在数据库领域,达梦、人大金仓和华为GaussDB等产品在金融、电信核心系统中替代Oracle、MySQL等国外数据库。中间件方面,东方通、宝兰德等企业突破国外垄断,为应用系统提供底层支撑。
国产大模型在2025年呈现爆发式发展,DeepSeek、智谱(Z.ai)和阿里通义千问(Qwen)是其中的突出代表。DeepSeek-V3.1拥有约6850亿参数和128K上下文长度,在编程基准测试(Aider benchmark)中达到71.6%的准确率,成本仅为1美元/任务,极具性价比。智谱开源的GLM-4.5系列采用混合专家架构,性能对标GPT-4,其API价格低至每百万token0.6美元,推动技术普惠。通义千问的Qwen3-Max-Preview参数量超万亿,在多项基准测试中领先,并支持256K上下文,已通过阿里云百炼平台开放商用。三者均坚持开源策略,推动国产大模型在性能、成本和应用生态上快速进步。
2022年11月份OpenAI推出的对话式人工智能产品ChatGPT是对人工智能产业的发展产生了深远的影响。ChatGPT基于Transformer架构,采用了包含1750亿参数的大规模语言模型(GPT-3.5)进行训练,能够通过理解和生成自然语言与用户进行交互。ChatGPT包含了强大的语言理解与生成,可以创作剧本、小说甚至编写代码;多轮对话与上下文记忆,使对话连贯且符合逻辑;多任务处理,如参加学术考试、翻译、撰写邮件等,展现了接近人类水平的认知与表达能力。ChatGPT确立了“预训练+提示”(Pre-training + Prompt)的新范式,推动AI研发从分散的垂直模型转向通用大模型,引发了全球科技公司对大规模语言模型的研发竞赛。产业上,它催生了新的水平化分工:上游依赖高性能算力芯片(如GPU)和云计算服务;中游涌现出大量基于大模型的Prompt工程平台;下游则重构了搜索引擎、智能客服、内容创作、教育辅导等应用场景。商业上,它加速了AIGC(人工智能生成内容)的商业化落地,OpenAI、微软、谷歌等巨头纷纷布局付费订阅服务,同时带动了数据标注、算力基础设施等相关行业的景气度提升。ChatGPT不仅推动了AI技术工业化生产的拐点到来,更重塑了人机交互方式,为各行业开启了智能化变革的新浪潮。
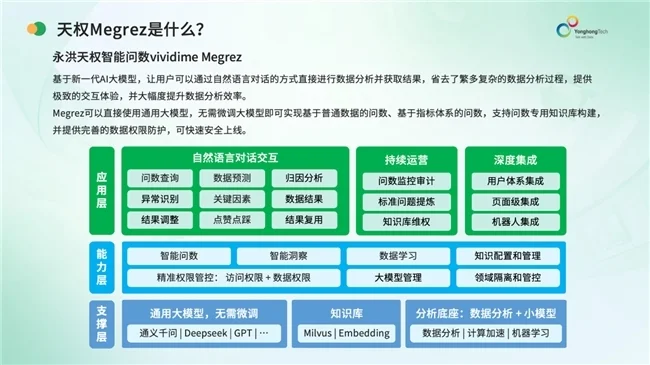
作为国内商业智能领域的领军企业,永洪科技一直致力于将前沿的科技应用到自身产品中,实现数据分析的平民化。在2021年11月发布的V9.4版本产品中,永洪科技就推出了基于自然语言输入获取数据的“数据问答”功能,代表了国内BI厂商在自然语言交互方向的早期探索。该功能允许用户通过中文自然语言直接提问,系统自动解析查询意图并生成可视化图表,显著降低了数据使用门槛。然而,传统基于关键词拆解和规则泛化的技术路径存在明显局限性:一方面,其语义理解高度依赖预定义的语法规则和同义词库,对复杂句式、多轮追问及口语化表达适应性有限;另一方面,规则系统泛化能力不足,需大量人工维护词表及映射逻辑,难以应对快速变化的业务术语和查询需求。
这是一条光明但曲折的技术道路。在2024年大模型的推理能力普遍比较有限,存在理解不准确、指令遵循差、输出格式不稳定等各种不足,并导致问数效果不达预期。而这也让联创团队面临巨大的挑战:其他团队快速推出了NL2SQL框架下的智能问数产品,在部分场景下有较好的表现,并得到了部分业务部门的初步认可。在这种情况下,一方面联合项目组邀请行业专家一起进行了多次研讨并确认,基于NL2SQL虽然可以实现简单查询,但是在数据安全保障和复杂问数场景下,存在明显的局限性,应该继续坚持Agent + NL2ABISkill的技术路线打造更好的能力。同时,永洪团队也通过自身努力来优化方案,一方面通过系统性的技能优化设计降低对大模型的理解和推理的能力要求,另一方面在后置环节增加容错机制来将降低对大模型输出格式的要求,通过这两个方向的努力,在短时间内实现了对该NL2SQL路线产品的超越,这也进一步坚定了联创团队的信心。
在取得初步成功之后,如何实现问数结果100%可信又成为联创团队新的难点。众所周知AI大模型的幻觉问题是当前业内最大的困扰,这个问题也困扰了联创团队很长时间。在长时间没有取得进展的情况下,永洪科技CEO亲自关注并提供了指导:问题的本质是一个数学问题,对于各种不确定性要识别出根本原因,回归到数学模型和数学推导来予以解决。在CEO的亲自关注下,永洪科技成立了AIGC突击队,将永洪科技各地研发中心的精英人才集中到北京总部进行重点攻关。在时间紧任务重的情况下,AIGC突击队发挥了敢打敢拼连续作战的精神,连续加班3个月,将问题归纳到8大类共25种问题,形成了抽象原则、正交原则、泛化原则等指导思想,并设计了一套驾驭大模型的方法论,最终实现了问数100%可信,问数准确率也从84%提升到了98%以上,达到并超越了95%的联创目标,这已经遥遥领先于市场上的同类大模型产品。

在达成可信和准确率方面的业务目标之后,项目进入业务场景验证的环节,此时又遇到了新的难题:由于算力方面的限制,实际场景下大模型的性能远低于预期,导致一次提问得到答案的耗时长达40秒,远超15秒的业务预期,此时已经逼近上线节点,联创团队再次面临巨大的挑战。联创团队双方成员没有退缩,而是积极分析并快速验证了三个方面的优化方案:第一,通过部署量化模型可以提升35%的性能;第二,通过对提示词工程的优化减少输入和输入的Token数可以实现15%的提升;第三,通过优化向量召回可以提升4秒左右。在双方领导层的大力支持和协调下,最终顺利地在上线前实现了这三个方面的优化,达成了简单问题10秒以内,复杂问题16秒以内的性能目标。